
第一步:安装Ollama
Ollama是一个支持大模型本地调用的工具,DeepSeek这种大模型的调用就是基于Ollama,所以大家首先双击“windows-OllamaSetup.exe”
Ollama是支持Windows端,Mac端和Linux端。
Ollama官网:https://ollama.com/download
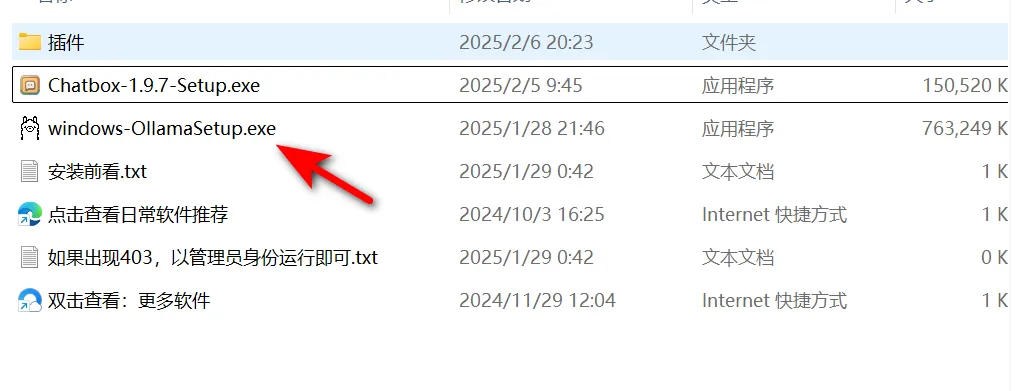
我以Windows为例,其安装过程是全英文,点击【Install】然后根据提示完成安装即可。
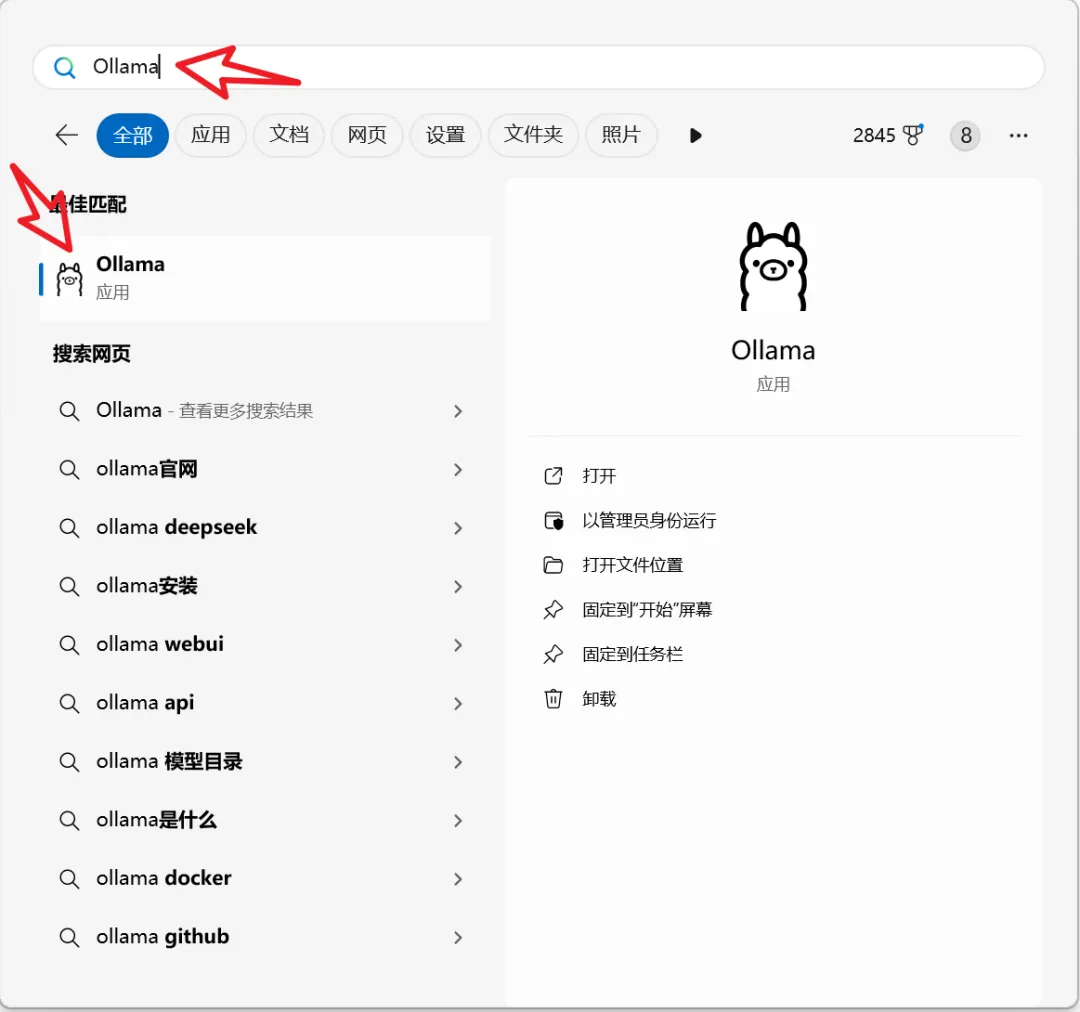
安装完成后,在电脑开始菜单,输入“Ollama”点击软件即可启动。
第二步:安装DeepSeek模型
安装完Ollama以后,我们就要开始安装模型了。
打开网页https://ollama.com/library/deepseek-r1
我们可以看到模型。
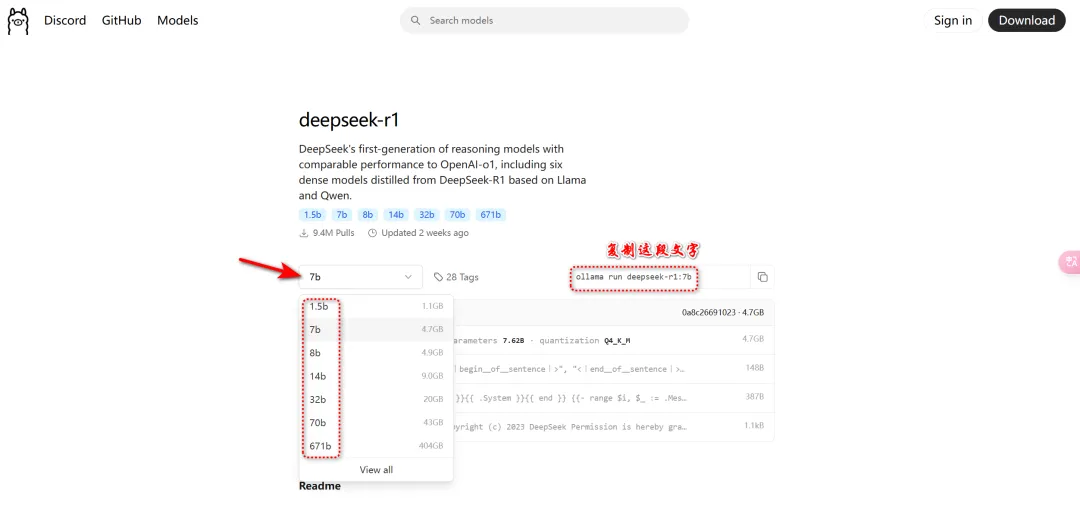
大家可以根据自己的电脑性能进行选择。
・1.5B:入门级别,硬件配置“4GB内存+核显”即可运行;
・7B:进阶级别,“8GB内存+4GB显存”可运行;
・32B:高性能设备推荐,“32GB内存+12GB显存”
这里推荐大家使用7B,绝大部分电脑都能运行。
如果选择7B,则复制“ollama run deepseek-r1:7b”按下“Win键+R”,输入“cmd”打开命令行窗口。
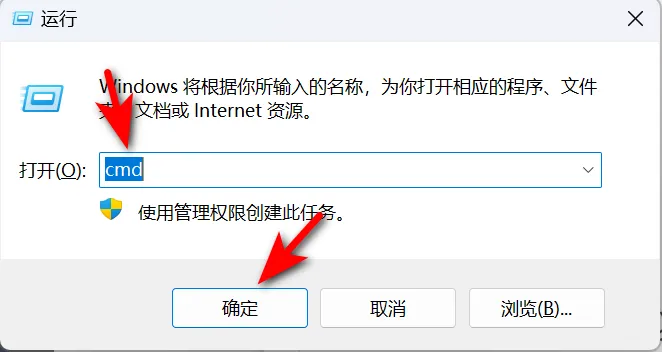
然后输入上面的那串文字“ollama run deepseek-r1:7b”,下图软妹电脑选择了32B,但事实是选择7B更好。
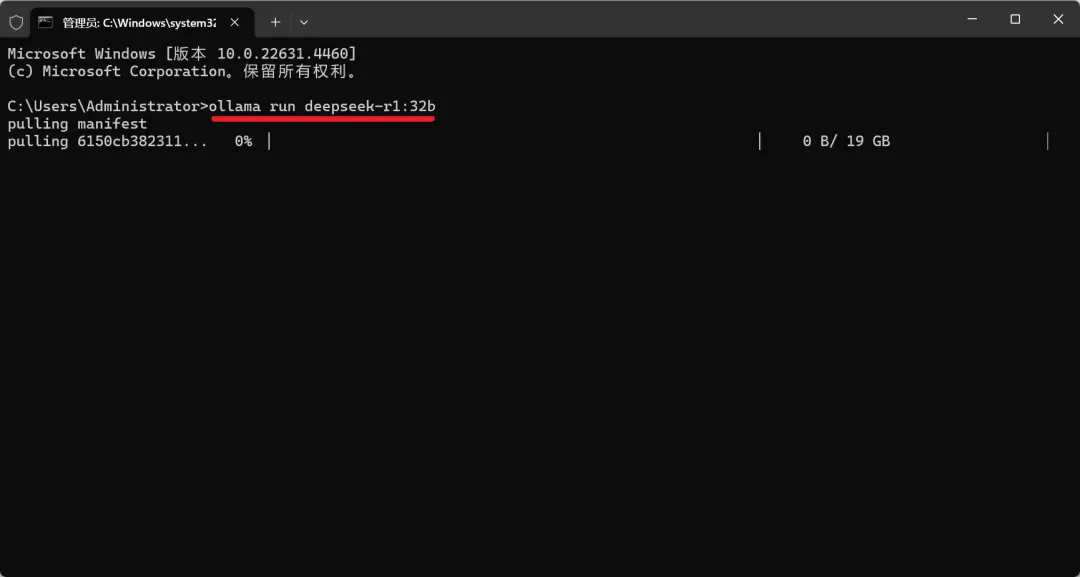
然后软件就开始下载大模型,我选择的32B需要下载19G的模型(再强调,大家不要选择32B,一般性能的电脑用7B即可),下载的速度有点慢,大家耐心等待即可。
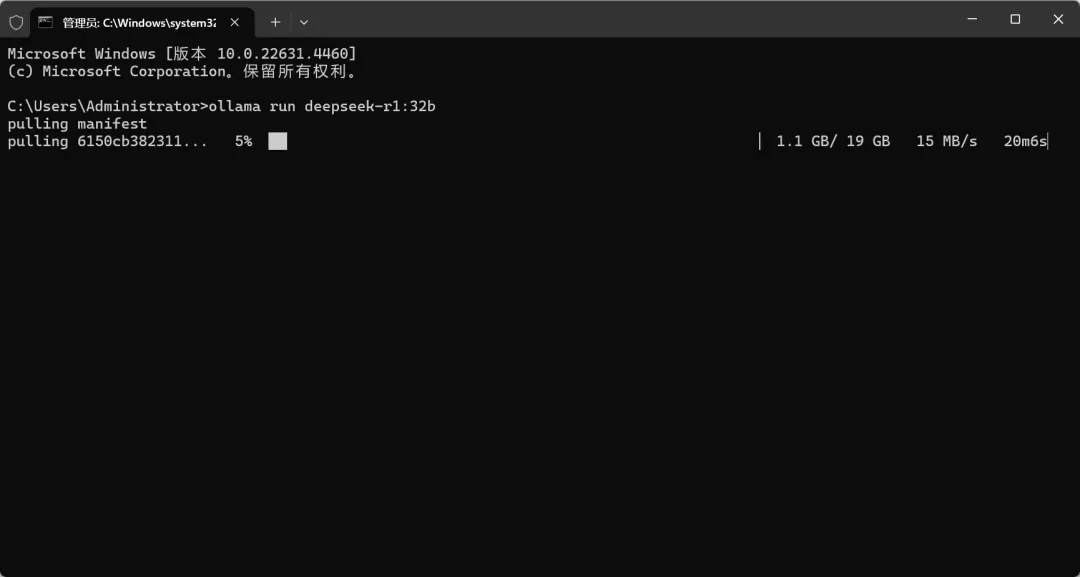
当出现“success”时,就代表下载安装成功了,就可以运行了。
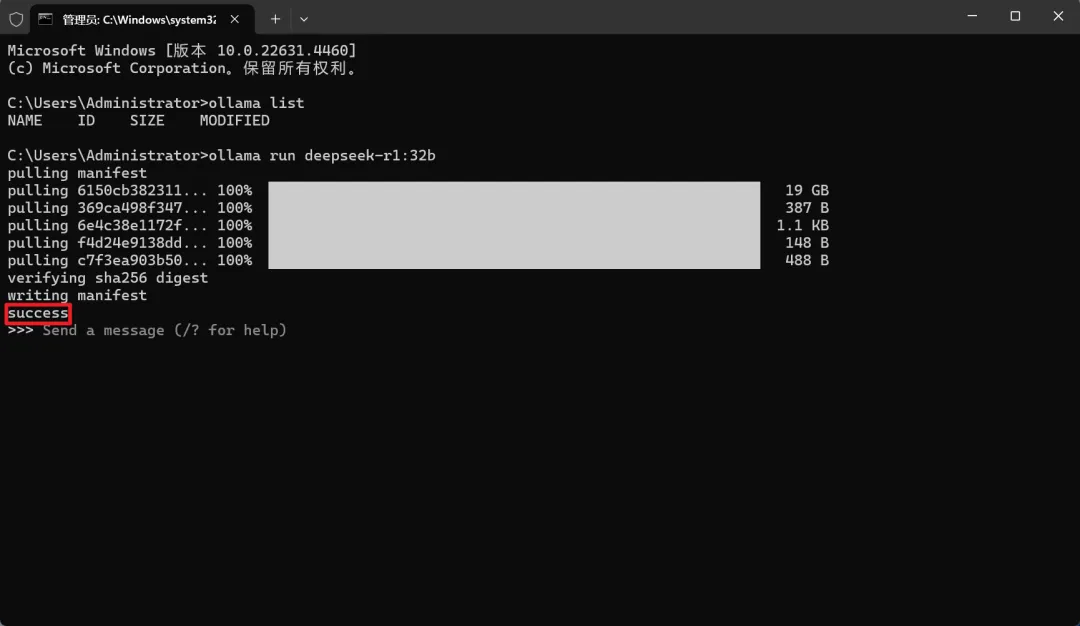
这时候你如果不要UI运行,则用命令窗口直接输入你想要的问题,DeepSeek就开始深度搜索,然后给出你想要的答案。
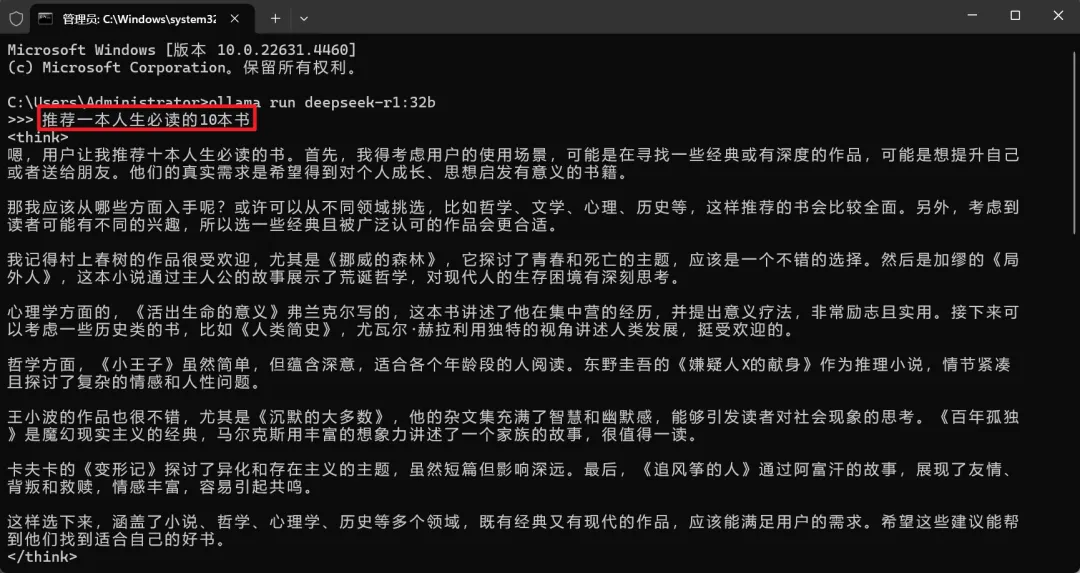
除了要调用cmd,输入你的模型的命令,操作有一丢丢麻烦。而且界面不好看,使用方面一点也不受影响!
如果不用界面,到这里大家部署完成,可以愉快的使用,下面的步骤都可以不用去安装了。
而如果想要界面,就得往下安装了。
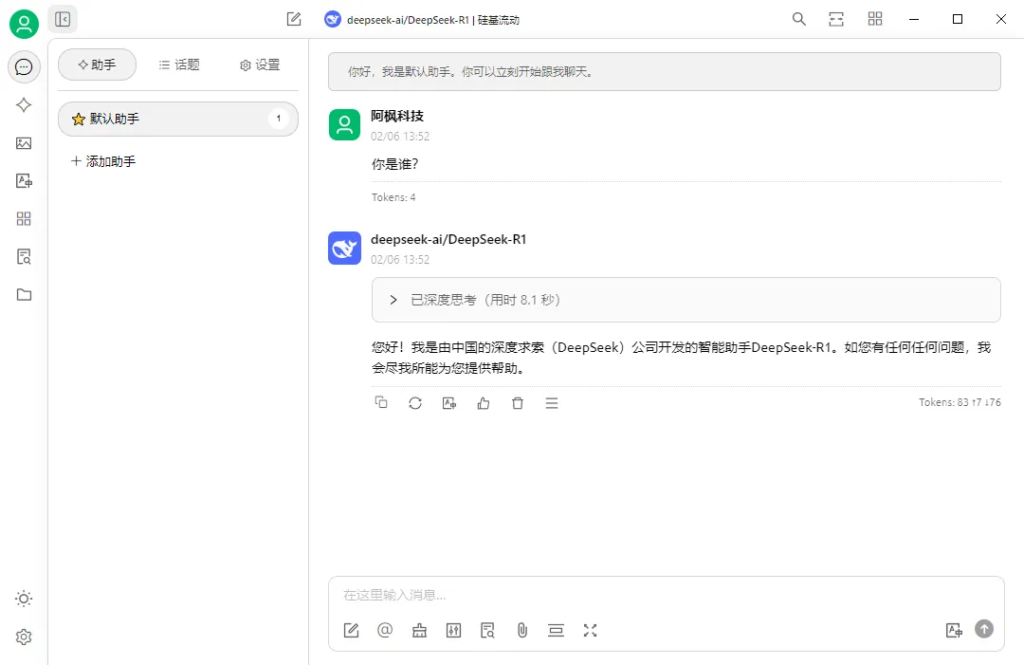
通过Cherry Studio调用模型
昨天文章有给大家介绍一款名为「Cherry Studio」开源的AI客户端,还没看的可以去看看昨天文章,这里就不多BB了,直接放上下载地址。
官网下载(Win+Mac+Linux):
https://cherry-ai.com/download
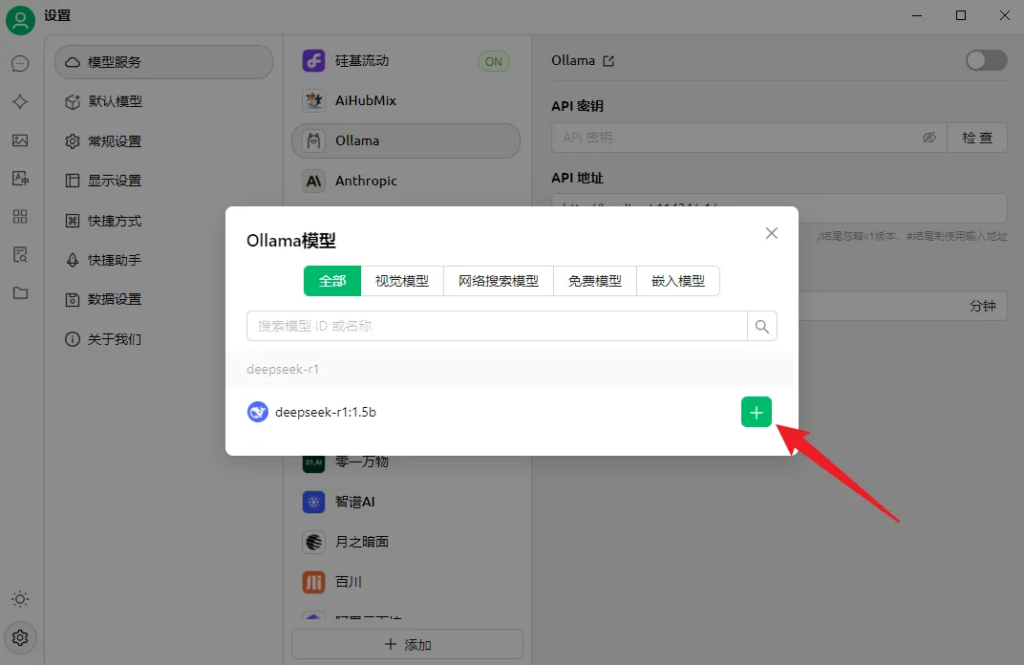
下载后打开客户端,进入设置,选择「Ollama」,API地址会自动填写,需要与下图中的地址保持一致,然后点击“管理”。
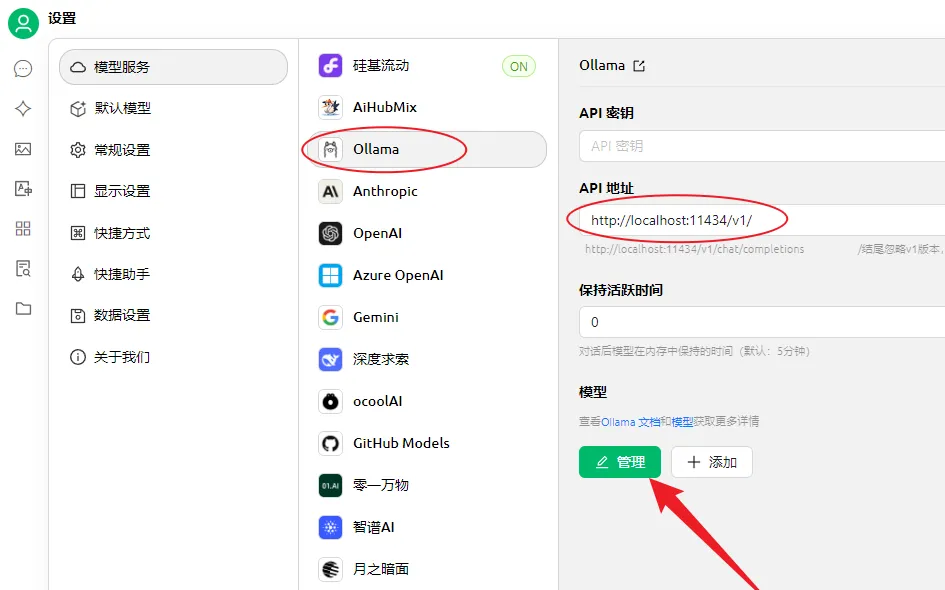
在弹出的窗口中可以看到自己本地的模型,点击右侧的按钮添加模型即可。
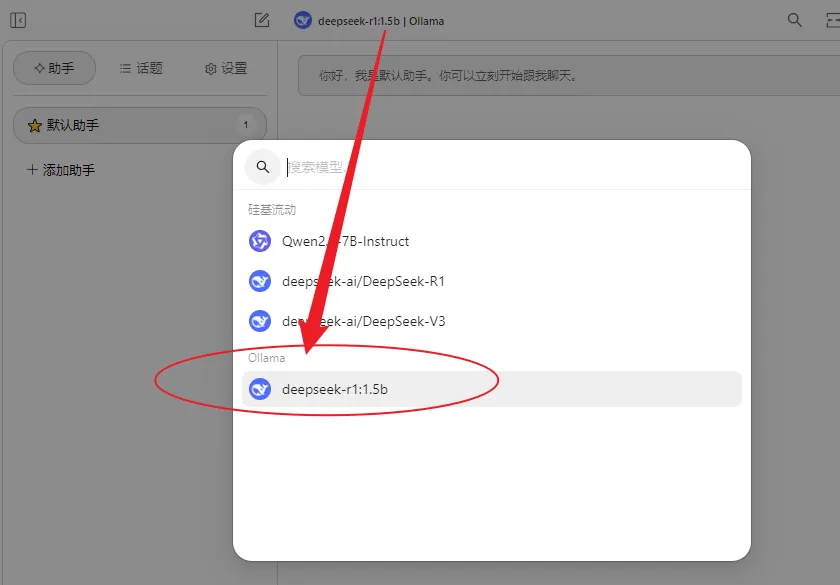
最后进入对话页面,点击顶部模型名称切换成本地部署的模型,至此大功告成。
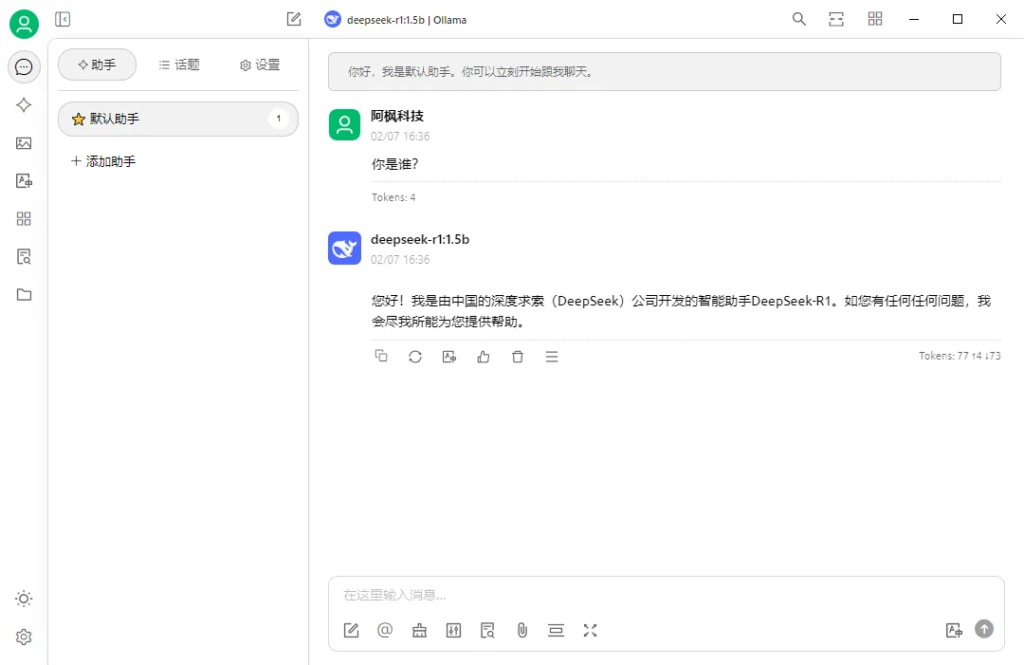
亲测可正常对话,只不过1.5b的版本有点蠢,有条件的尽量试试大参数模型,否则自己部署也只是浪费时间。
通过安装ChatBox调用模型
软件中有Windows 64位的客户端,大家默认安装即可。
官网:https://www.chatboxai.app/zh#download下载
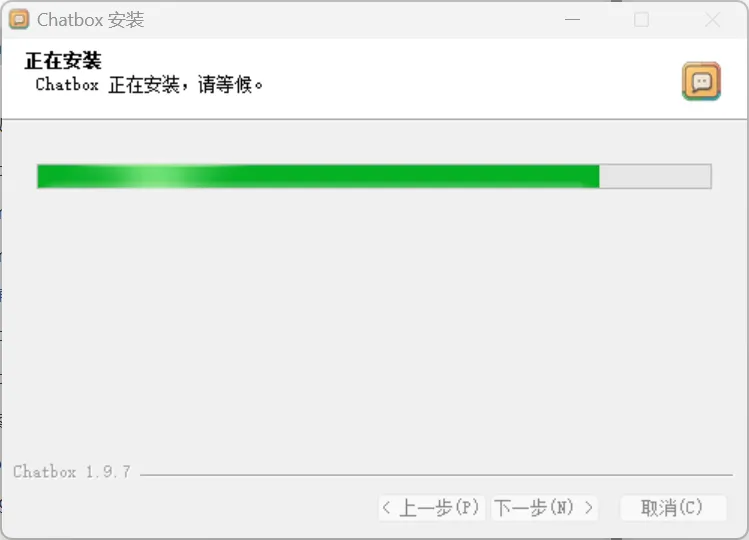
如果想要Mac端、Linux端,大家可以去官网:https://www.chatboxai.app/zh#download下载。
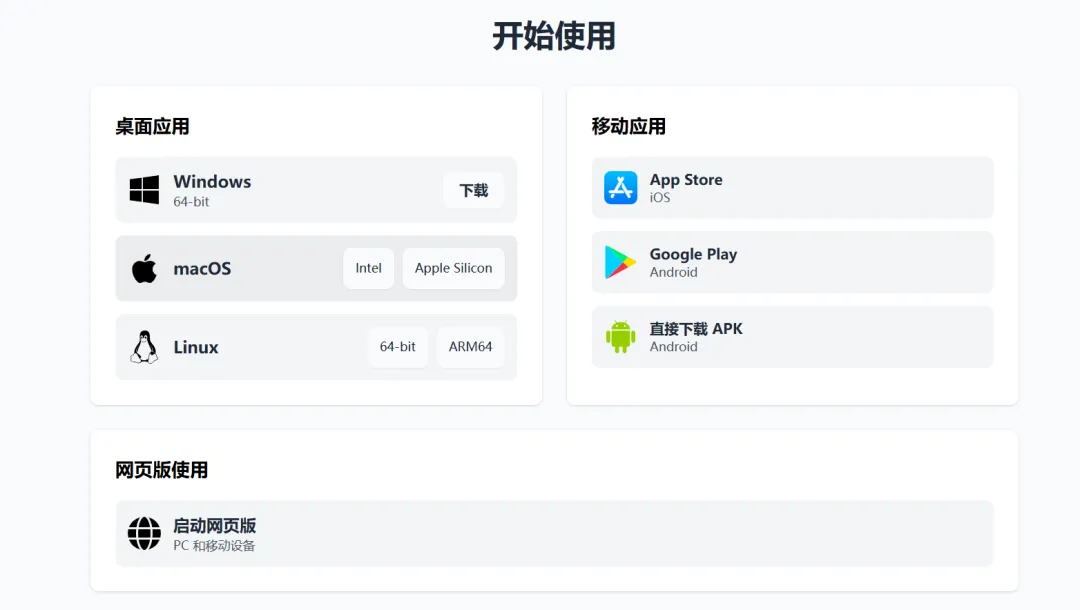
安装完成后,点击左边的【设置】
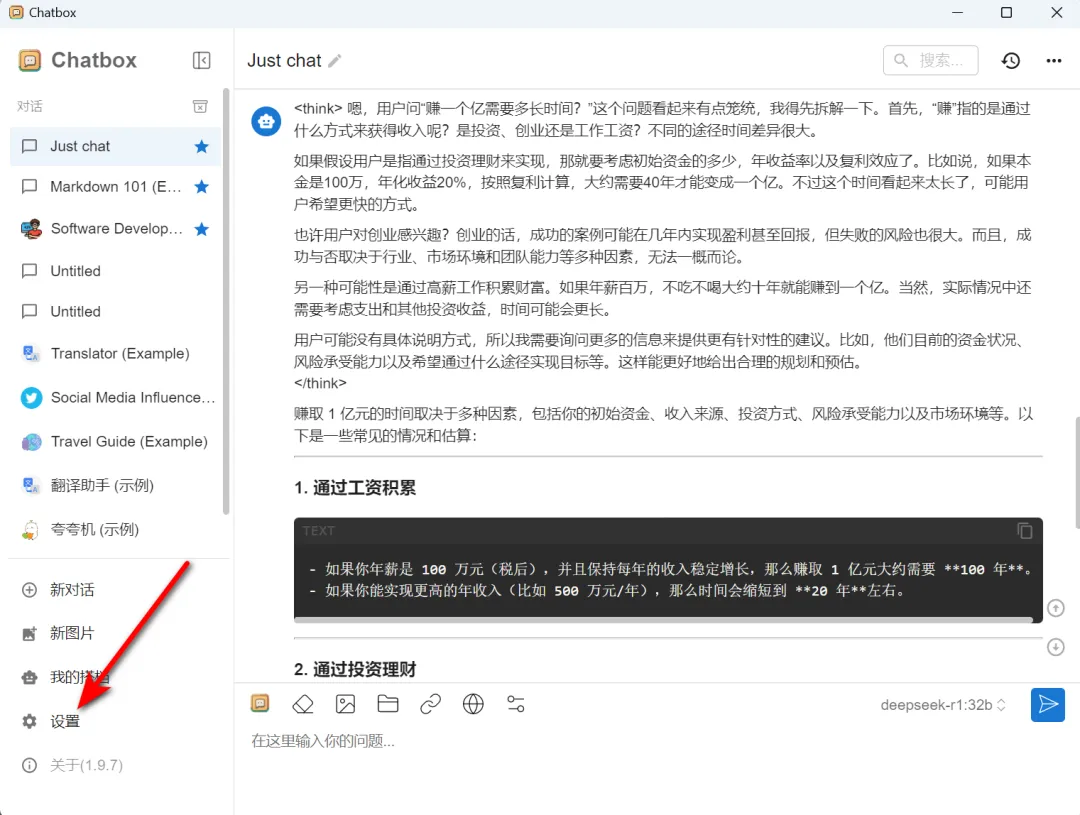
然后选择“OPENAI API”,依次填写API密钥、API域名、选择模型等等,注意我这里的是“32B”,填写的是“ollama run deepseek-r1:32b”,你们选择“7B”的要填写“ollama run deepseek-r1:7b”
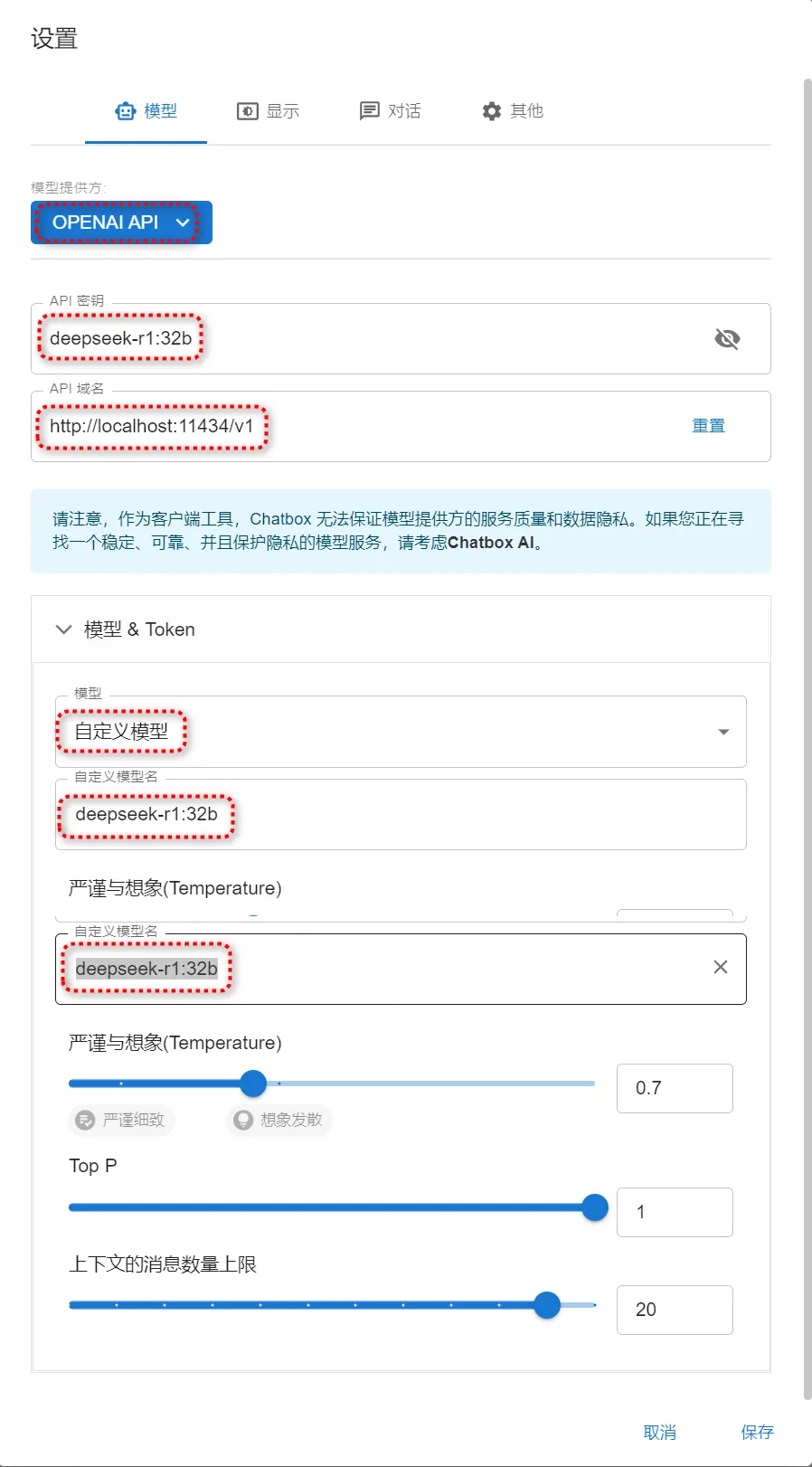
填写好后点【保存】,然后软件就可以调用DeepSeek进行对话了,输入你的问题,软件即给出你想要的答案。
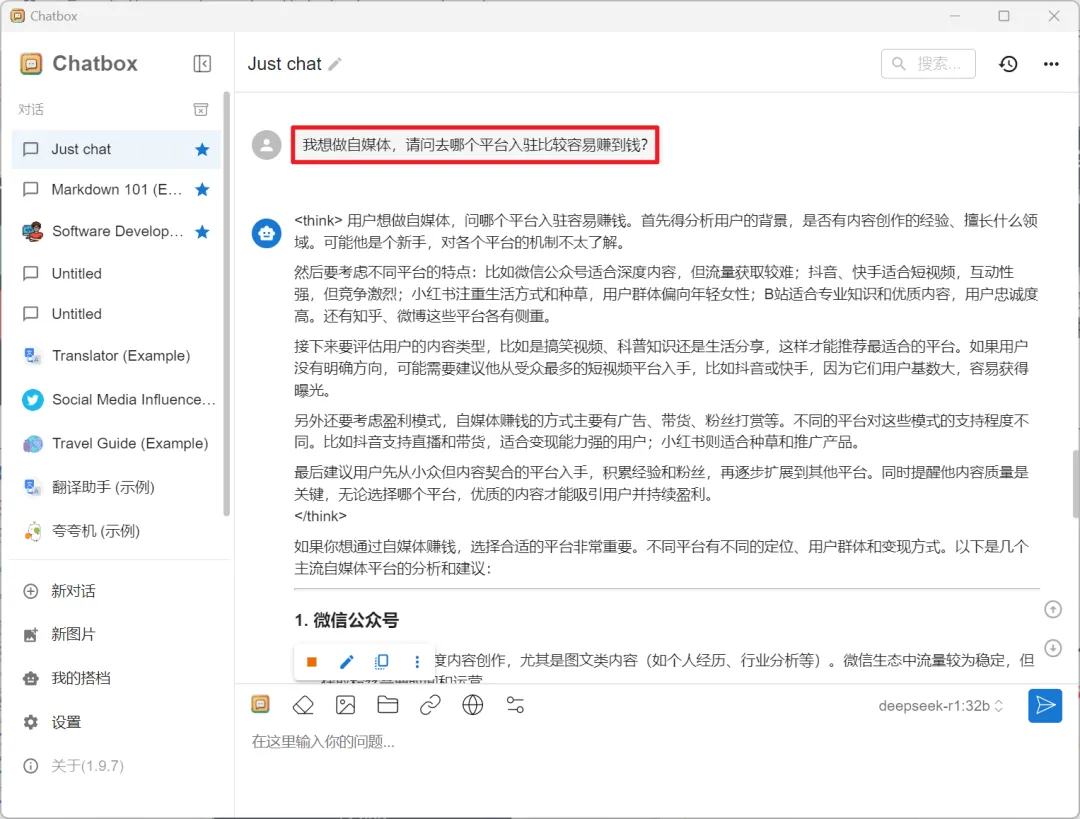
说真的,有点吃配置,但是不会出现服务器繁忙的情况。
首先注册一个「硅基流动」的开发者账号,无需实名认证,通过下方链接注册可免费获取2000万Tokens,注册成功自动到账👇
通过「硅基流动」白嫖满血版R1模型
注册地址:
https://cloud.siliconflow.cn/i/hXFPFroU
这2000万Tokens完全足以应对你的不时之需,当DeepSeek官网陷入频繁,这就是你的后盾
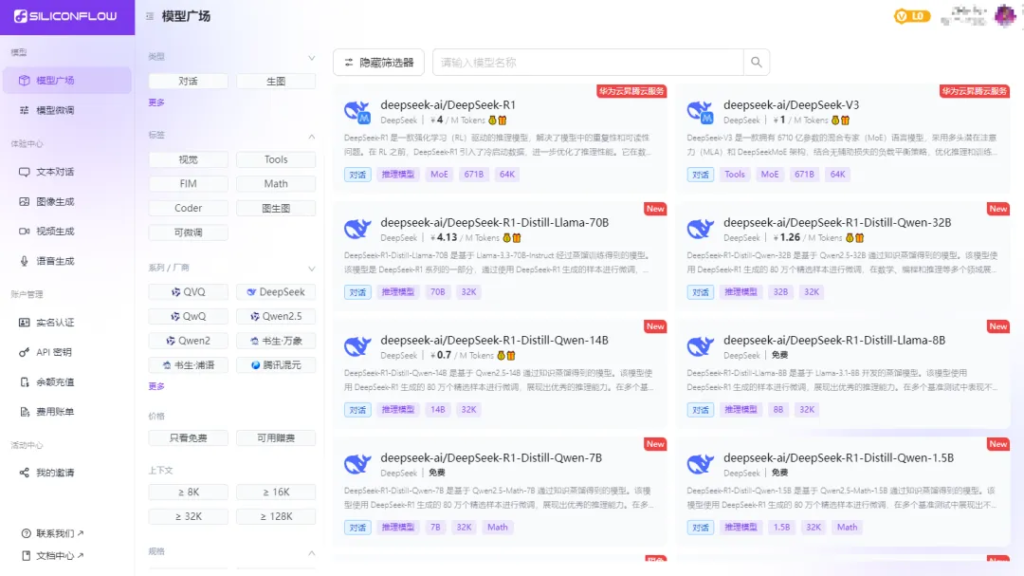
一.在线使用
在模型广场首页有很多DeepSeek的模型,如果想要体验满血版R1,就认准这个671B的R1模型,点击“在线体验”即可使用。
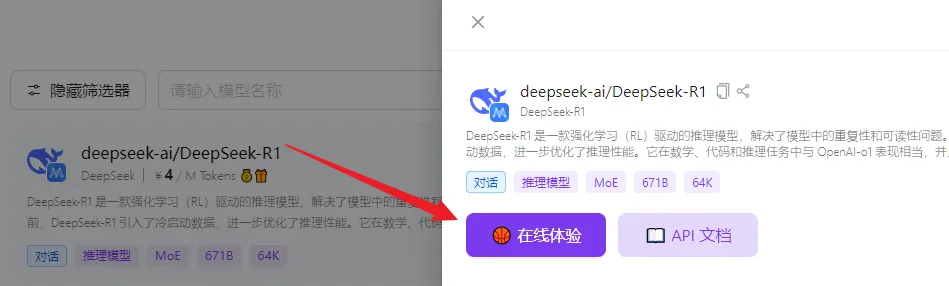
这里的R1模型用的都是专线,所以用起来非常稳定,回复速度也更快。
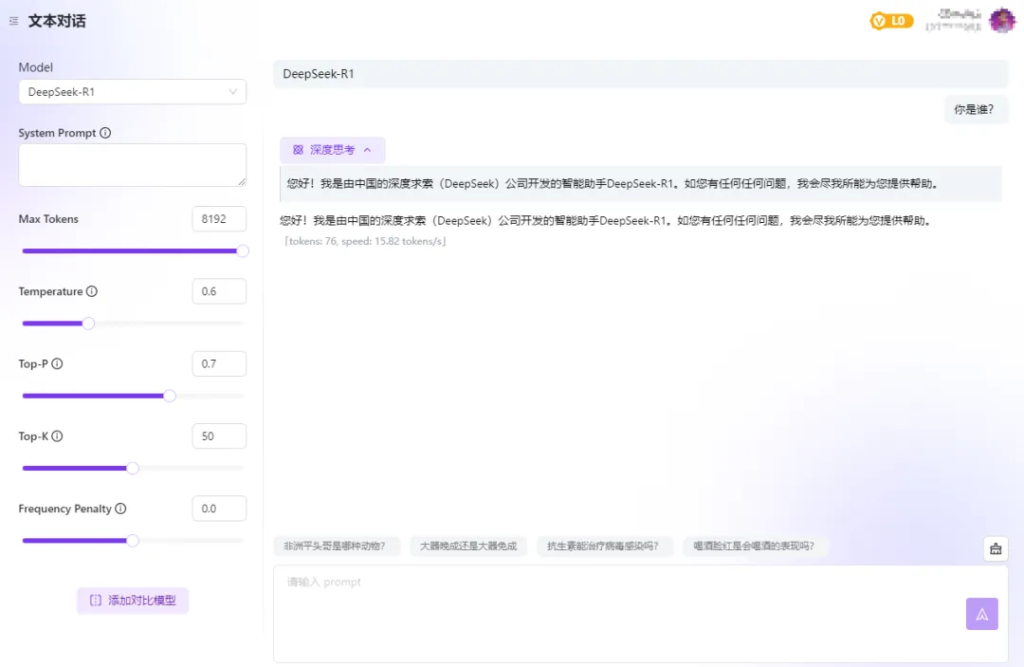
当然,你也可以通过调用API的形式,在本地客户端使用满血版R1模型。
发布者:海棠网
文章网址:https://www.haitangw.cc/7237.html
如果您喜欢本站,可以收藏本网址,方便下次访问!
软件中的广告/弹窗/群号等信息切勿相信,注意鉴别,以免上当受骗!
本站软件全都是免费分享,仅供学习参考,严禁倒卖盈利!